
Data is the raw material but on its own, holds little value. Before data can create value for a business, it needs to be refined and analysed; this process is referred to as data analytics. The ultimate goal of data analytics is to turn raw data into insight which can be acted on to create business value.
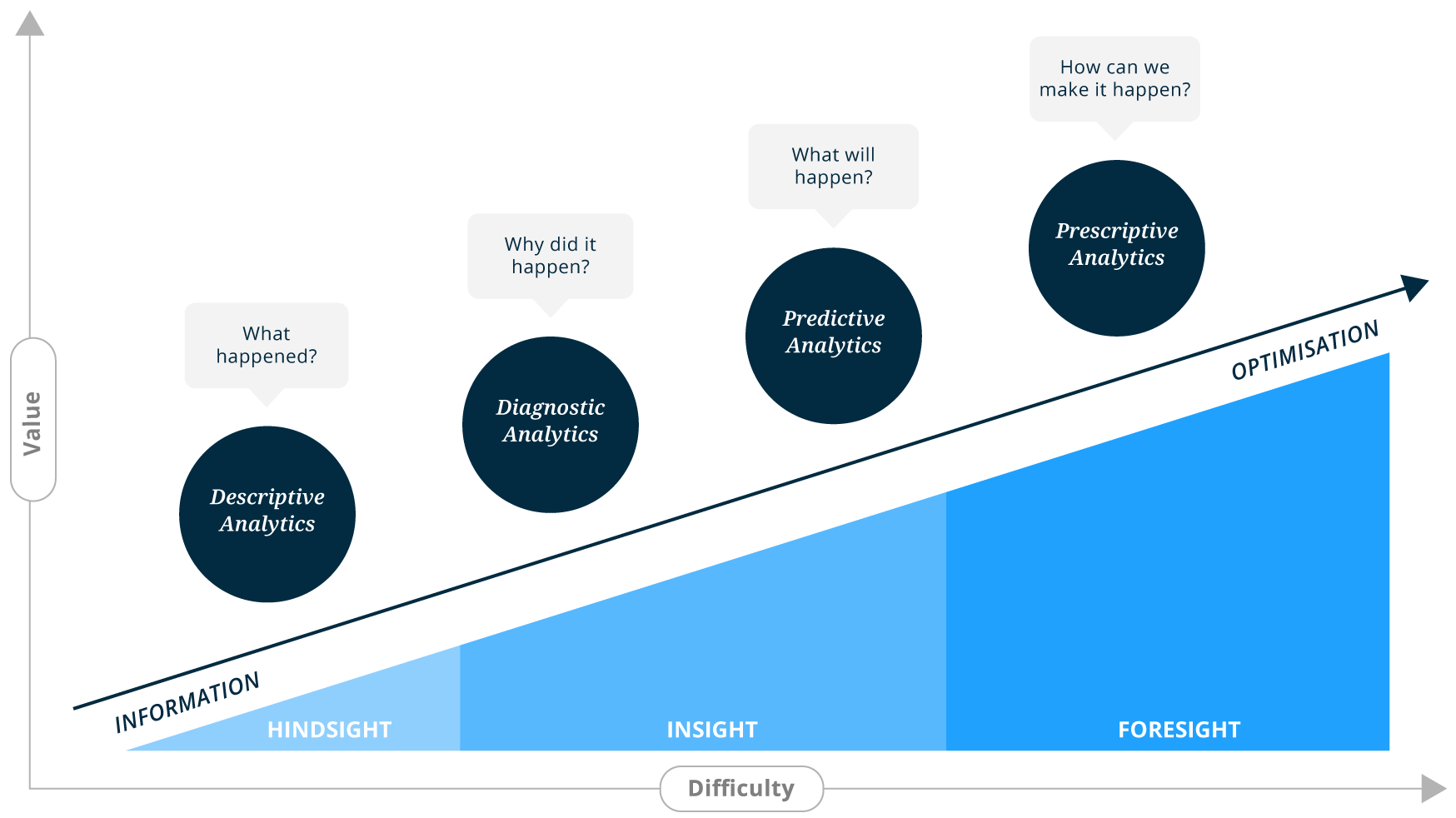
Descriptive analytics is the most commonly used form of data analytics.
This form of analytics describes and presents historical data in a way that can easily be summarised and understood. It answers the question of, “What happened?”. This allows businesses to learn from past events and understand how they may influence the future. Descriptive analytics is usually the starting point to inform, diagnose and prepare data for advanced analytics techniques.
Example uses of descriptive analytics
Visit our PredictPrice, PredictInventory or PredictCustomer page for domain-specific examples.
Predictive analytics is the application of data mining, statistical modelling and machine learning to predict “What is likely to happen in the future?”.
While there is no crystal ball to see into the future, predictive analytics enables you to make an educated guess using mathematics and statistics, not gut-feel. Predictions are typically created by analysing historical data, using machine learning, then attempting to fill future data based on the patterns and relationships in that data.
Unlike descriptive analytics which focuses on the past, predictive analytics focuses on future events which did not yet happen; this means we can do something about them. We use predictive insight to make informed decisions and effective business strategies based on probabilities.
Example uses of predictive analytics
Learn more about our PredictRetail models or learn more about predictive analytics.
While descriptive analytics focuses on what happened, and predictive on what may happen, prescriptive attempts to answer “How do we make it happen?”.
What is the best course of action to ensure that a simulated outcome is achieved?
Prescriptive analytics is the combination of internal and external data, business rules, boundaries and simulation, to find the best path to the desired outcome. This is the final stage of the analytics journey and comparatively the most complex and challenging to manage, requiring deep domain expertise and ongoing fine-tuning.
Learn more about prescriptive analytics.
Big data refers to massive amounts of data that cannot be stored or processed in a traditional relational database. It is the use of advanced analytics, including predictive modelling, against these large data sets containing both structured and unstructured data, from diverse data streams. Big data will typically have a large volume, velocity or variety of data. The fundamentals of data analytics apply equally to relational or big data analytics; mainly the tools used are different.
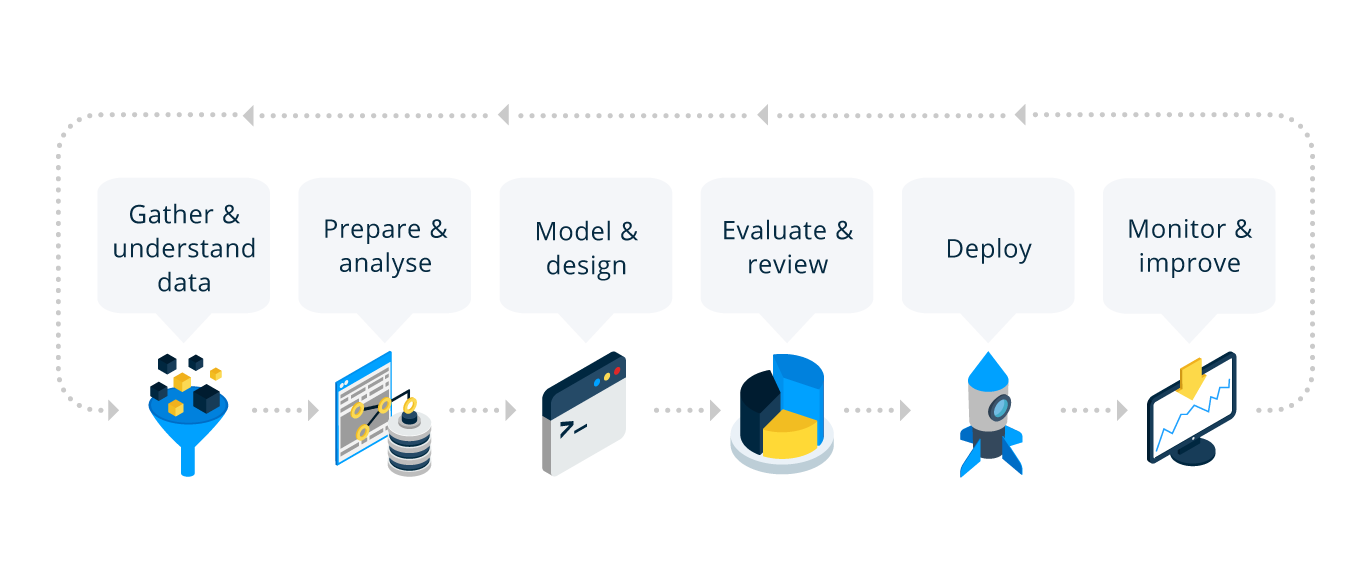
Setting clear and measurable goals is at the core of any data analytics process, and the entire lifecycle revolves around this primary objective. To define the goals and objectives, you need to be asking the right questions. Domain knowledge and descriptive analytics help immensely to determine the right questions.
When starting a data analytics project and setting goals, at a bare minimum, ask yourself these questions. If there was a dashboard with a gauge and the purpose of the project is to ‘move the needle’:
Appoint a data analytics “champion” − an executive, or a person with authority, to spearhead the implementation of the organisation’s data strategy. Change management is crucial for success as the workforce transitions from using gut feel and experience to using data and analytics to make better decisions.
After requirement gathering and defining objectives and measurements, it’s time to collect relevant data. Preferably lots of historical data. Predictive modelling is most accurate when there is sufficient data to establish strong trends and relationships.
Every dataset has its own nuances that are business-specific. For example, transaction types could cause every row in the dataset to have a different meaning, depending on this transaction type. There could be a historical event that caused a significant but temporary deviation in data, for example, a fire or natural disaster that disrupted business operations. These nuances are only known internally and typically not well documented. It’s not enough to just gather the data, it’s important to collaborate closely with the internal teams in order to uncover these nuances and outliers, and gain a solid understanding of what the data means, at its core.
Domain knowledge and experience help tremendously during this step. You need to “know what you don’t know”, and looking at data is not enough. You need a solid understanding of the operational processes as well.
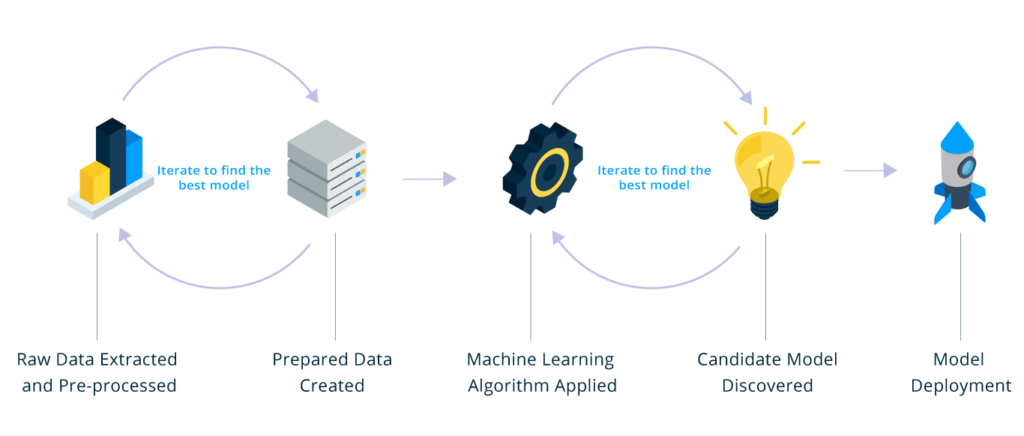
Data is the fuel that powers data analytics; inferior data produces inferior results, so data goes through several phases of refinement and preparation. Data is extracted, transformed and loaded (ETL) before feature extraction and modelling begins. It is a crucial step that will often take a large chunk of the total project time, and with good reason.
Data gathering, cleaning and merging are used to identify and remove errors, outliers and inconsistencies affecting data quality and accuracy. The goal is to create repeatable data pipelines that continuously feed raw data into big data and relational database storage. Data Engineers typically handle this process.
When the data cleaning and ETL steps are complete, Data Scientists can apply advanced analytics techniques, including machine learning and predictive modelling, to convert clean data into insight and business value. Because we are predicting future events, there always needs to be a way to validate the accuracy and estimate uplift during the development and training of the model, and not at a future date.
There needs to be a level of trust in the accuracy before it is actioned operationally. Trust is achieved by referencing back to the ‘gauge and needle’ we aim to move and the project’s primary objective. Model assessment reports and dashboards are used to track accuracy and overall uplift. Assessment reports allow data scientists to apply various algorithms and machine learning techniques and benchmark each against the assessment dashboards until a satisfactory level of accuracy is achieved and a top candidate is identified.
Model assessment is typically benchmarked by time-boxing and splitting the data into a training and validation dataset. For example, the training dataset could be data older than six months; this dataset is used to train the machine learning model to predict the future. The validation dataset could be data from 6 months ago up to today; this dataset is used to assess the accuracy of the predictions and the trained model without having to wait. In essence, this enables us to validate the model accuracy over six months in a simulated environment but using real-life data.
Through this process, we will not only be able to identify the best-performing algorithm or method, but we will also be able to estimate the accuracy and uplift with a high degree of confidence. If the model is X% accurate for the past six months, we can safely assume that the same level of accuracy, or better, will be achieved when trained with a full dataset to predict the following six months.
When the model is trained, tested and benchmarked, predictions and insight need to be actioned and utilised operationally. To use an analogy, predicting the winning lottery numbers and not buying a lottery ticket invalidates all the effort; this is where the importance of a business champion and custodian comes into play. This champion is typically an executive sponsor or someone with authority to handle change management to action the insight and measure the uplift. To ‘buy the lottery ticket’!
The last step is the ongoing monitoring of the model’s performance. The context around us changes continuously, and new data sources become available, data-drifts, unexpected events happen (corona!), etc. These changes could affect performance. It’s essential to monitor and continuously improve the accuracy and performance of the models in order to maximise business value.
When the predictions are actioned, they will produce new sets of data, or data could be enriched using external data sources. There will always be new data that needs to go back into the business analytics lifecycle in order for the predictive models to learn and improve continuously.
Business analytics lifecycle is cyclical and only improves over time as more relevant data becomes available.
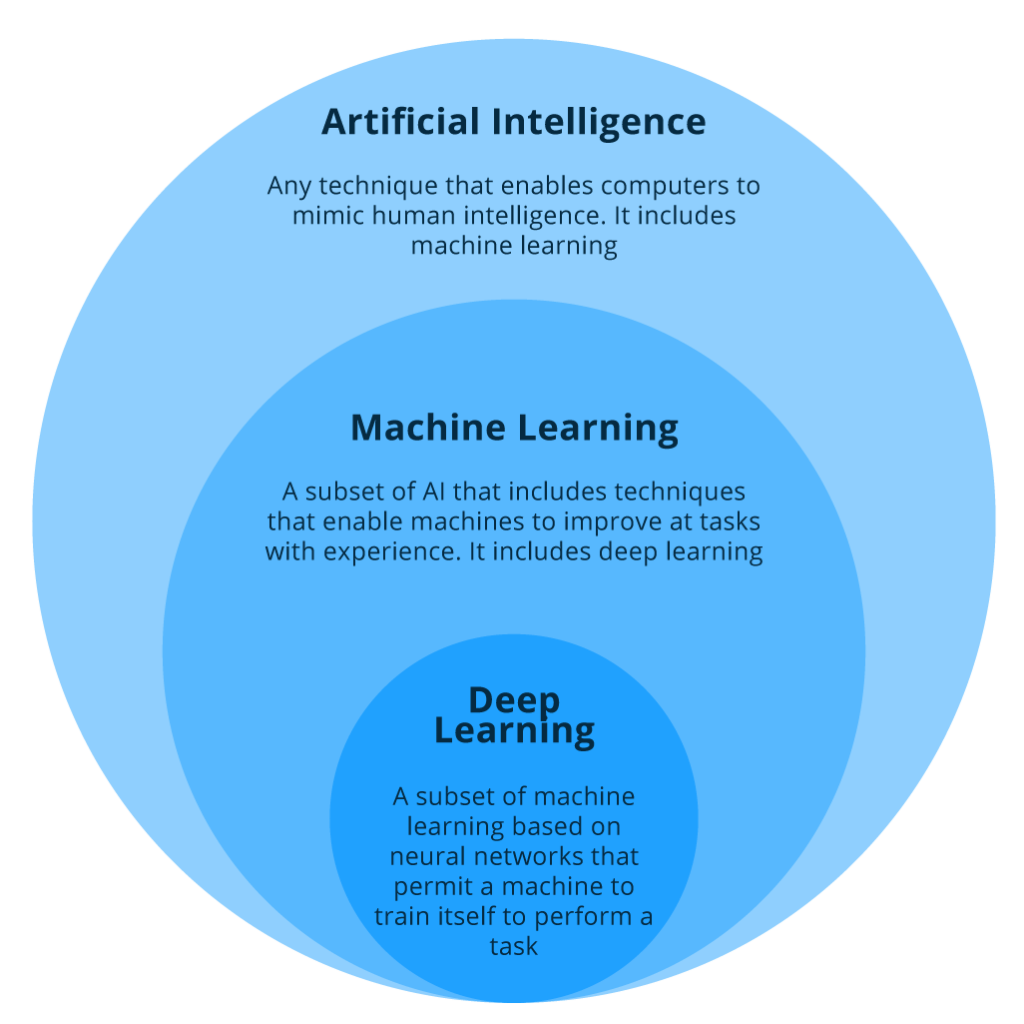
The primary potential of AI lies in its ability to collect large volumes of data at high speed, recognise patterns, learn from them, and enable better decision-making.
Machine learning refers to a technique that gives computer programs the ability to learn from data, without explicitly being programmed to do so. Just like humans learn from experiences, machine learning enables programs to learn from historical data, allowing businesses to make decisions based on the trends and relationships in the data. Model accuracy is affected by the volume of data available to learn from, the strength of the trends, and the algorithms used.
To help conceptualise machine learning, let’s look at how we might apply ML to build personalised customer recommendations in a retail environment.
Sales and transaction histories usually have patterns and relationships in the data, some are obvious, but most are not. If you have a large number of customers, it would be challenging to analyse trends for each customer individually and consistently determine the most viable product or service to trigger an intent. ML can quickly solve this challenge. Historical data is used to train and teach a machine-learning algorithm to analyse relationships between products, customers, price, transactions, clickstreams and other features or data properties, to statistically determine in real-time the products or services with the highest probability of conversion. The algorithm learns on an ongoing basis and adjusts to the changing context and available data. The trained ML model is, in essence, a “rules engine” that is trained for one purpose, to increase sales, without explicitly being programmed to do so by a programmer. When the trends and patterns in the data change, so will the rules to always maintain maximum efficiency.
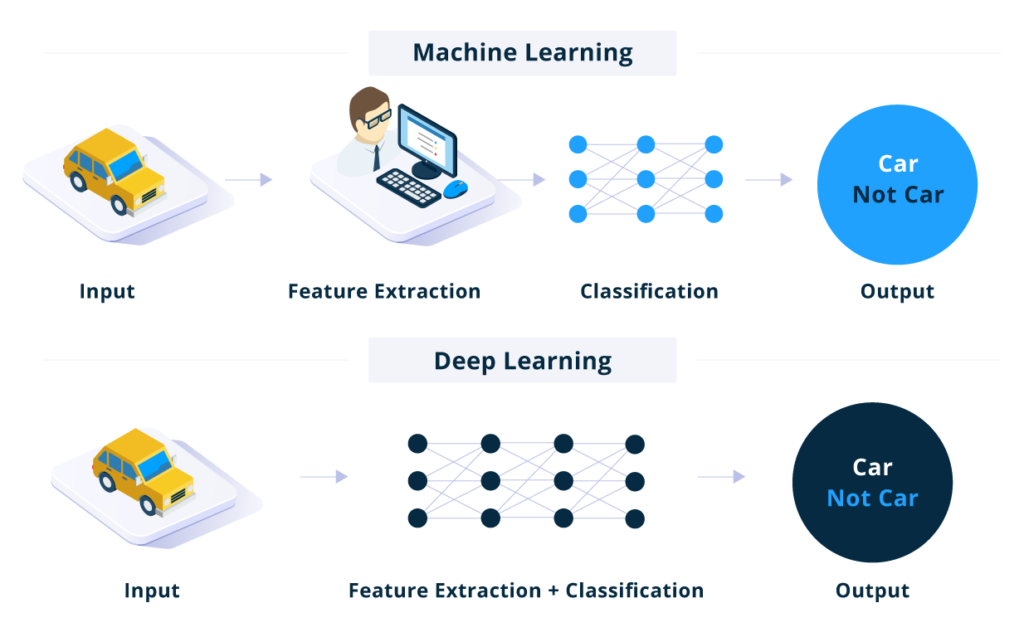
The more recent deep learning is a subset and evolution of machine learning. It is modelled based on how the neurons in the human brain work. DLg uses multiple layers of algorithms called artificial neural networks to analyse complex data without human intervention. The most human-like AI, such as autonomous vehicles, image and voice recognition, natural language processing, etc., are made possible by deep learning. DL is particularly effective when there is a massive volume of data, the data is not structured and labelled, or the problem is too complex to explain or solve with traditional machine learning.
“In traditional Machine learning techniques, most of the applied features need to be identified by a domain expert in order to reduce the complexity of the data and make patterns more visible to learning algorithms to work. The biggest advantage of Deep Learning algorithms is that they try to learn high-level features from data in an incremental manner. This eliminates the need for domain expertise and hardcore feature extraction.” Source
The primary potential of AI lies in its ability to collect large volumes of data at high speed, recognise patterns, learn from them, and enable better decision-making.
Machine learning refers to a technique that gives computer programs the ability to learn from data, without explicitly being programmed to do so. Just like humans learn from experiences, machine learning enables programs to learn from historical data, allowing businesses to make decisions based on the trends and relationships in the data. Model accuracy is affected by the volume of data available to learn from, the strength of the trends, and the algorithms used.
To help conceptualise machine learning, let’s look at how we might apply ML to build personalised customer recommendations in a retail environment.
Sales and transaction histories usually have patterns and relationships in the data, some are obvious, but most are not. If you have a large number of customers, it would be challenging to analyse trends for each customer individually and consistently determine the most viable product or service to trigger an intent. ML can quickly solve this challenge. Historical data is used to train and teach a machine-learning algorithm to analyse relationships between products, customers, price, transactions, clickstreams and other features or data properties, to statistically determine in real-time the products or services with the highest probability of conversion. The algorithm learns on an ongoing basis and adjusts to the changing context and available data. The trained ML model is, in essence, a “rules engine” that is trained for one purpose, to increase sales, without explicitly being programmed to do so by a programmer. When the trends and patterns in the data change, so will the rules to always maintain maximum efficiency.
The more recent deep learning is a subset and evolution of machine learning. It is modelled based on how the neurons in the human brain work. DLg uses multiple layers of algorithms called artificial neural networks to analyse complex data without human intervention. The most human-like AI, such as autonomous vehicles, image and voice recognition, natural language processing, etc., are made possible by deep learning. DL is particularly effective when there is a massive volume of data, the data is not structured and labelled, or the problem is too complex to explain or solve with traditional machine learning.
“In traditional Machine learning techniques, most of the applied features need to be identified by a domain expert in order to reduce the complexity of the data and make patterns more visible to learning algorithms to work. The biggest advantage of Deep Learning algorithms is that they try to learn high-level features from data in an incremental manner. This eliminates the need for domain expertise and hardcore feature extraction.” Source
Argility is a Google Cloud Build Partner. We utilise a microservices architecture and best-of-breed Google Cloud Analytics tools, including Google Big Query, Google Dataflow, Google AI, and Google Vertex AI to handle any data transformation or machine learning workload with ease.
